上個月被派了幾個工項,
其中一個是解我們開單員拍到的車牌照片。
相信各位做影像的同行在驗證自己演算法的時候,
總是像我一樣眼見為憑、需要把圖片秀出來對吧?
在很多的 OpenCV 教學文裡面都教我們用這行程式碼關掉視窗:
cv2.imshow('Image', img)
cv2.waitKey(0)但是用這行程式碼的問題是如果你按了視窗右上角的 “X” 來關掉視窗,
那麼你的程式就會卡住,因為 OpenCV 不知道視窗被關掉了,
所以視窗的程序就繼續執行跟你演。
我每次遇到這狀況就快要中風,
為了避免各位同行也中風我在此提供解決方法。
cv2.imshow('Image', img)
while True:
if (cv2.getWindowProperty('Image', cv2.WND_PROP_VISIBLE) <= 0 or cv2.waitKey(1) > 0):
cv2.destroyWindow('Image')
break
原理是去檢查名稱叫做 Image 的視窗狀態,
如果他被關掉了,那就把視窗的程序結束掉讓程式就繼續進行。
至於為什麼要放 waitKey(1) 而不是 waitKey(0),
那是因為 waitKey(0) 放在條件式裡面會像王寶釧苦守寒窯十八年,
等你在視窗按下任意鍵。
如果你又按 “X” 把視窗結束掉了,那就真的老死不相往來了。
那你說 CPP 裡面怎麼辦呢?有 CPP 的版本嗎?
我也覺得很奇怪,Python 版的 OpenCV 理論上是 bind CPP版 的 OpenCV ,
兩邊實現應該會一樣?
但是 CPP 中 waitKey(0) 可以偵測視窗關掉(也就是按右上角”X”也能關掉視窗程序)。
以上,謝謝指教。

本篇文章來自 想知道網戀對象有沒有修圖嗎?試試看這款修圖偵測機器人! 的續篇,
不是,我是說有些人可能不適合做立委、適合做總統!
所以我用 CPP 實現了需要數學運算的 DCT 方法,
這邊比較需要注意的是因為我選用的讀圖方式是 OpenCV 的 CPP 函式庫,

相關開源我更新在:
https://github.com/wuyiulin/GraphAppBot
想要測試一下這個服務:
如果有任何問題歡迎聯絡我:
wuyiulin@gmail.com
最近公司開始有新想法,加上 ESP32 要讀寫資料,
開始在研究怎麼在純 C 裡面讀寫 config.ini。
因為經手的專案都搭配 Makefile 編譯,
所以本篇也會一併紀錄 Makefile 設定眉角。
我的環境是 Ubuntu 22.04,
apt 裡面沒辦法直接裝 libconfig,
於是首先先下載 libconfig 的壓縮包:
從別人那邊轉貼的安裝流程:
# 解壓縮
tar -zxvf libconfig-你下載的版本編號.tar.gz
# 進入工作資料夾
cd libconfig-你下載的版本編號
./configure
# 編譯
make -j8
# 檢查編譯有沒有壞掉
make check
# 開始安裝
sudo make install
# 複製檔案到你想要的地方,這邊一定要 sudo 不然 .so 會進不去
# 原版教學
sudo cp -d ./lib/libconfig* /usr/lib
# 想用 Makefile 包進專案
sudo cp -d ./lib/libconfig* /usr/include
# 檢查安裝路徑是否正確
sudo ldconfig -v
在你的 Makefile 做兩件事情
1. 確定 CFLAG 裡面包含 /usr/include(通常會包)
2. -LDFLAG 後面加上 -lconfig
接下來就能讀寫 config.ini
接下來就能
config_t cfg;
config_setting_t *setting;
config_init(&cfg);
//讀取整份文件
config_read_file(&cfg, "config.cfg");
//讀取特定的 value
const char *value;
config_lookup_string(&cfg, "section1.key1", &value);
//寫入特定的 value 至暫存
setting = config_lookup(&cfg, "section1.key2");
config_setting_set_string(setting, "new_value");
//將暫存寫入文件
config_write_file(&cfg, "config.cfg");要特別注意的是這個套件支援的 ini格式有點不一樣
這格式長這樣:
section:
{
key1 = value1
key2 = value2
key3 = value3
}
完美 謝謝指教
前陣子在咱們一群影像愛好者的群組開始流傳一套程式,
一套號稱能檢測愛情動作片封面詐欺的程式!
什麼?天底下有這等好事?
於是我找到了開發這套程式的仁兄要到了原始論文,
認為他實現得不夠完美,間接促使我完成這項服務。
這篇文章可以幫你得出一個修圖參考值
(但某些情況不適用,文後會補充說明。)
接著會介紹論文以及背後數學原理,
對於檢測服務比較有興趣可以直接跳到後面。
原理
本文是 Analyzing Benford’s Law’s Powerful Applications in Image Forensics 這篇論文的延伸應用:
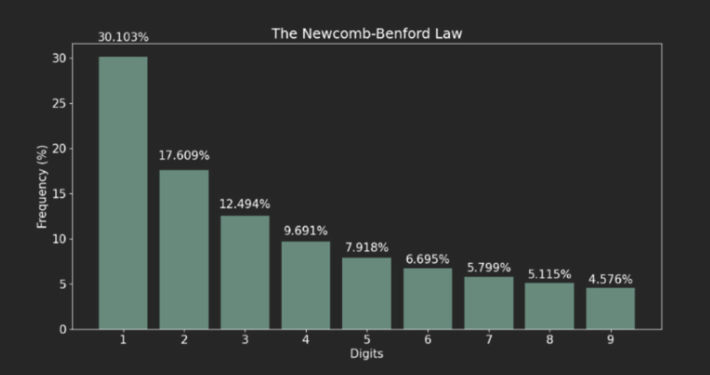
要講解這篇論文就要先解釋什麼是 Benford’s Law?
Benford’s Law 的概念就是人類世界中隨機數其實並不隨機,
其中數據的首位數字是遵循某種規律,這個規律就是 Benford’s Law。
Benford’s Law 公式:
$F_a = log_{10}{(frac{a+1}{a})}$, for all a = 1,2,…,9
這樣算起來會呈現由首位數字出現比率是 1 往 9 遞減的一個分佈:
舉個 Benford’s Law 的例子,
如果他們沒有說謊的話,這一萬人的存款首位數字應該會符合 Benford’s Law。
而論文本意是拿這個結論做二次壓縮來估測 JPEG 的壓縮率,
有興趣的大家可以自己閱讀一下論文。
實作

身為一個影像從業者,
一定要做到比內建函式庫快!
俗話說得好:
要看一個人會不會做立委,就要看他怎麼做立委。
我是說要加速就要從數學看起,所以讓我們來看一下公式:
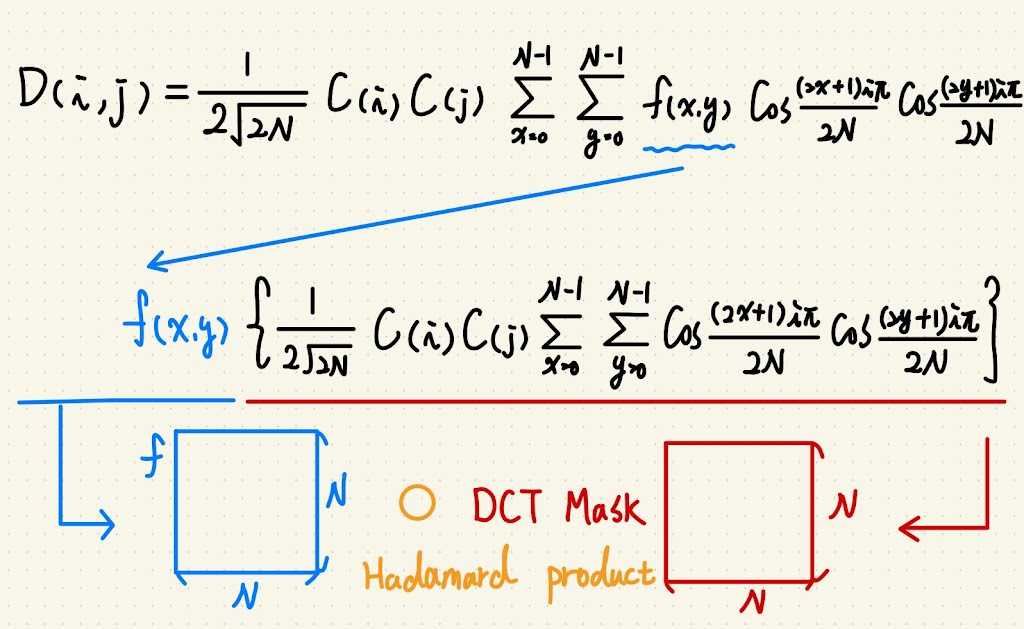
其中 $D(i, j)$ 是轉換後的值,$i, j$ 是位置參數;
$f(x, y)$ 是原始圖片的亮度值,$x, y$ 也是位置參數。
發現亮度值可以提出來,其中位置參數可以自己組一個矩陣相乘,
我們暫且把包含所有 $i, j$ 組合的稱為母矩陣。
這個母矩陣可以重複用,就不用每個區塊都要算。
(原始圖片會被 N*N 的小區塊分割,N 通常是 8。)
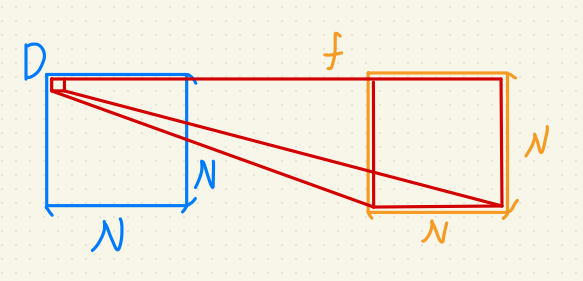
因為一組 $i, j$ 負責一組子矩陣,
所以如果輸出入尺寸相同,母矩陣大小為: $N * N * N * N$
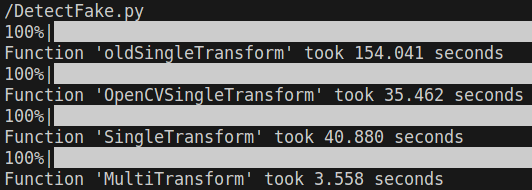
於是我用這方法寫了一個 Mask 法,
的確速度與 OpenCV 內置函數比肩了,但是還沒有超越(#。
再加速
於是我又對平行運算生起了一絲邪念,
如果我宣告一組共享記憶體紀錄首位數字,
並對計算每個區塊的計算採取平行運算呢?
起初我是用 Lock 方法,後來發現這樣設計寫入的時候會有 Race Condition 問題,
後來便採取 Lock free 實作,缺點是佔用的記憶體較多。
數據判讀
目前線上提供服務的機器人都是使用 DownSample 方法做計算。
特別需要說明的是手機原生相機就會做白平衡、明暗部校正,
尤其是 iPhone 做得非常優秀。
開源
原始論文使用 Uncompressed Colour Image Database 資料庫,
探討使用原始無損圖片如何估計 JPEG 壓縮率,
所以本文的物理意義是估算原始無損圖片與輸入圖片的差異度。
本文估計值僅供參考,
窮盡科技之力後不如鼓起勇氣約網戀對象出來走走!

這邊提供 OpenCV 編譯後崩潰的可能解決方法:
我的環境是 OpenCV 4.5.4、Ubuntu 22.04,
並使用 g++ 11.4.0 編譯我的專案。
我遇到的情境問題是,我得到一包 C/C++ 的專案,
裡面用 Makefile 來整合編譯專案,裡面包含我自己寫的一段高斯濾波程式碼。
這貨整包編譯時沒有出錯;
獨立把高斯濾波程式碼放到另一個編譯、運行也都沒有出錯。
但當我在源碼裡面運行這段高斯濾波程式碼時”有機率”會出錯:
int ksize = 3;
cv::Size size = image.size();
int width = size.width;
int height = size.height;
cv::Mat blurred_image(height, width, CV_8UC1, cv::Scalar::all(0));
cv::GaussianBlur(grey, blurred_image, cv::Size(ksize, ksize), 0, 0);
然而我給定的高斯核大小為 3×3,
非常奇怪,程式會跳說高斯核定義不是奇數,所以不合法:
error: (-215:Assertion failed) ksize.width > 0 && ksize.width % 2 == 1 &&
ksize.height > 0 && ksize.height % 2 == 1 in function 'createGaussianKernels'
除此之外,當我想使用旋轉圖片、在圖片上畫點的功能也全部失效,但是編譯又沒有出錯,
這件事情真的是非常奇怪。
因為是運行時錯誤,於是我先用 GDB 檢查了函式是否重複定義:
然而並沒有,這就奇了怪了。
後來我開始埋 log 想辦法抓鬼,也完全抓不到。
解決方法:
把專案的 Makefile 打開,有關於 OpenCV 的部份改寫,
讓 Makefile 繞過 pkg-config ,手動給定 OpenCV.hpp 還有 libopencv_XXX.so 的路徑。
如果我的 OpenCV.hpp 放在 /usr/include/opencv4/opencv2 底下,
那就把 CFLAGS+= 裡面加入 -I/usr/include/opencv4;
libopencv_XXX.so 放在 /usr/lib/x86_64-linux-gnu 下面,
那就把 LDFLAGS += 裡面加入 -L/usr/lib/x86_64-linux-gnu。
原版:
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV
LDFLAGS+= `pkg-config --libs opencv4`
COMMON+= `pkg-config --cflags opencv4`
endif
改寫成:
ifeq ($(OPENCV), 1)
COMMON+= -DOPENCV
CFLAGS+= -DOPENCV -I/usr/include/opencv4
LDFLAGS+= `pkg-config --libs opencv4`
LDFLAGS+= -L/usr/lib/x86_64-linux-gnu -lopencv_core -lopencv_highgui -lopencv_imgproc -lopencv_imgcodecs
COMMON+= `pkg-config --cflags opencv4`
endif
完美解決
雖然我另外一份獨立的 CPP 檔案能夠用 pkg 找到 OpenCV 也能編譯,
pkg PATH 裡面也有 OpenCV,暫時不知道哪裡耦合到了,
先留紀錄改天遇到再來深究。
若有錯誤請聯絡我 – wuyiulin@gmail.com

這篇主要介紹 Linux/Windows 兩個平臺使用 Intel 內顯資源開發 OpenCL 的解決方案,
並且不用重新編譯核心,不像這篇太 Hardcore 了xD
首先你當然要確定自己的 Intel CPU 有沒有支援 OpenCL?
先參考 Supported APIs for Intel® Graphics,
但是只是參考就好,因為我在裡面用一塊號稱支援 OpenCL 2.0 的晶片支援了 OpenCL 3.0。
我認為 Intel 並不知道自己在做什麼。
筆者在此使用 Ubuntu 22.04 做為開發環境,
在此 OS 下你只需按照這篇安裝 intel i915 驅動,
然後驗證驅動有沒有裝好?
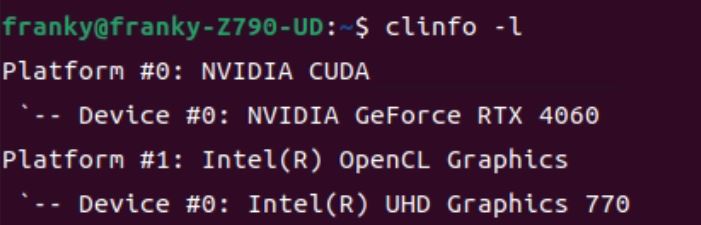
sudo apt-get install clinfo
clinfo -l如果有裝好應該會像筆者的畫面這樣:
接著你想要用 gcc 或 g++ 開發都沒問題,
甚至用 make 編譯專案也可以直接車過去,這就是 UNIX 帶原生編譯器的好處。
Windows
筆者在此使用 Windows 10 做為開發環境,
在 Windows 不用特別去裝 intel 驅動,理論上一定會自行下載。
但 Windows 因為沒有原生編譯器的優勢,所以你必須選擇編譯器流派。
如果你沒有要編譯整個專案,只想自己寫一點東西來驗證,
我推薦使用 MinGW64 就好。
MinGW64 只要再額外安裝 lib 及 headers 便可以執行後續驗證。
使用這份 .C程式碼來驗證:
#include
#include
int main() {
cl_uint platformCount;
clGetPlatformIDs(0, nullptr, &platformCount);
if (platformCount == 0) {
std::cerr << "No OpenCL platforms found." << std::endl;
return 1;
}
cl_platform_id* platforms = new cl_platform_id[platformCount];
clGetPlatformIDs(platformCount, platforms, nullptr);
std::cout << "Number of OpenCL platforms: " << platformCount << std::endl;
for (cl_uint i = 0; i < platformCount; ++i) {
char platformName[128];
clGetPlatformInfo(platforms[i], CL_PLATFORM_NAME, sizeof(platformName), platformName, nullptr);
std::cout << "Platform " << i + 1 << ": " << platformName << std::endl;
}
delete[] platforms;
return 0;
}
如果你需要 CMake 整份專案,
那先跟我大喊一聲:Fuck you Intel!
原因是網路上安裝 Intel OpenCL 的教學大多都需要這份:
Intel SDK for OpenCL applications
但是這份已經停更了。
根據 Intel 官方表示後續會分散在各 OneAPI 部件裡面支援,
所以我們會被引導到這個 Intel 官方文件頁面:
Intel Tools for OpenCL™ Applications
我試過了都沒用,不要浪費時間跟 Intel 官方文件在那邊鬧。
他們最近不知道想推 SYCL 還是什麼東西,總之沒有支援。
我會說沒有支援的原因是因為:
你要能 CMake 一份專案最主要要引用兩份東西,
一份叫做 OpenCL.lib,一份叫做 CL.h or CL.hpp。
按照 Intel 官方文件裝完上述套件都找不到 CL.h or CL.hpp,
就算找來 KhronosGroup 版本的 CL.h 代打也會有問題,
天知道 Intel 怎麼寫他們的 OpenCL.lib?
另外一個不推 Intel 解決方案的原因是近年來他們都綁 MSVC,
代表我要載又肥又呆的 Virtual Studio,個人不是很喜歡。
怎麼辦呢?
打不贏就加入!
我在開發死線前尋尋覓覓,發現敵人就在本能寺!
發現敵人的敵人就是朋友,AMD 有做這個欸?
我能不能用 AMD 的文件驅動 Intel CPU 呢?
哇靠!可以!
大家只要下載這個來安裝,並記住安裝路徑。
他會提供 CMake 最需要的 OpenCL.lib 及 CL.h。
接著在你的 CMakeLists.txt 裡面修改,
通常上面兩行要新增 OpenCL.lib 及 CL.h 的路徑,
下面兩行應該本來就有,新增一下就好。
find_path(OPENCL_INCLUDE_DIRS CL/cl.h PATHS /path/to/opencl/include)
find_library(OPENCL_LIBRARIES OpenCL PATHS /path/to/opencl/lib)
include_directories(${OPENCL_INCLUDE_DIRS})
target_link_libraries(YourExecutable ${OPENCL_LIBRARIES})
這樣應該就能成功編譯專案了!
如果本篇內容有誤歡迎聯絡我:
謝謝大家!

REF.
OpenCL入门一:Intel核心显卡OpenCL环境搭建

最近上班遇到一些圖片顏色偏離原色,
身為影像工程從業者就會想自己寫 3A算法來校正。
而自動白平衡便是 3A 中的其中 1A – 南湖大山!
而自動白平衡便是 3A 中的其中 1A – Auto White Balance
自動白平衡的核心就是解決圖片色偏的方法,
大都是找到圖片中的參考值,
再用參考值及不同方法去對整張圖片做校正。
像是灰色世界算法就是拿全圖片的加總的三通道均值當作參考值,
再拿這個參考值除以三通道分別均值做成三通道的增益,
得到三通道增益後分別對通道相乘。
今天提到的完美反射核心,它的概念是相信圖片中有一群接近白色的區塊,
因為 RGB or BRG 的世界裡面 (255, 255, 255) 就是白色嘛,
所以有點像找到這塊邊長為 255 的正方形中那群最遠離原點 (0, 0, 0) 的那群點。
找到那群點後,再求得這群的均值作為參考值,
參考值除以各通道的均值就能得到各通道的增益,
最後再拉回去與原圖相乘 -> 結案。
def AutoWhiteBalance_PRA(imgPath, ratio=0.2): # 自動白平衡演算法_完美反射核心, 0 < ratio <1.
BGRimg = cv2.imread(imgPath)
BGRimg = BGRimg.astype(np.float32) # 將資料格式轉為 float32,避免 OpenCV 讀圖進來為 np.uint8 而造成後續截斷問題。
pixelSum = BGRimg[:,:,0] + BGRimg[:,:,1] + BGRimg[:,:,2]
pexelMax = np.max(BGRimg[:,:,:]) # 求三通道加總最大值作為像素值拉伸指標
row , col, chan = BGRimg.shape[0], BGRimg.shape[1], BGRimg.shape[2]
pixelSum = pixelSum.flatten()
imgFlatten = BGRimg.reshape(row*col, chan)
thresholdNum = int(ratio * row * col)
thresholdList = np.argpartition(pixelSum, kth=-thresholdNum, axis=None) # 由右至左設定閾值位置,並得到粗略排序後的索引表。
thresholdList = thresholdList[-thresholdNum:] # 取得索引表中比閾值大的索引號
blueMean, greenMean, redMean, i = 0, 0, 0, 0
for i in thresholdList:
blueMean += imgFlatten[i][0]
greenMean += imgFlatten[i][1]
redMean += imgFlatten[i][2]
blueMean /= thresholdNum
greenMean /= thresholdNum
redMean /= thresholdNum
blueGain = pexelMax / blueMean
greenGain = pexelMax / greenMean
redGain = pexelMax / redMean
BGRimg[:,:,0] = BGRimg[:,:,0] * blueGain
BGRimg[:,:,1] = BGRimg[:,:,1] * greenGain
BGRimg[:,:,2] = BGRimg[:,:,2] * redGain
BGRimg = np.clip(BGRimg, 0, 255)
BGRimg = BGRimg.astype(np.uint8)
return BGRimg


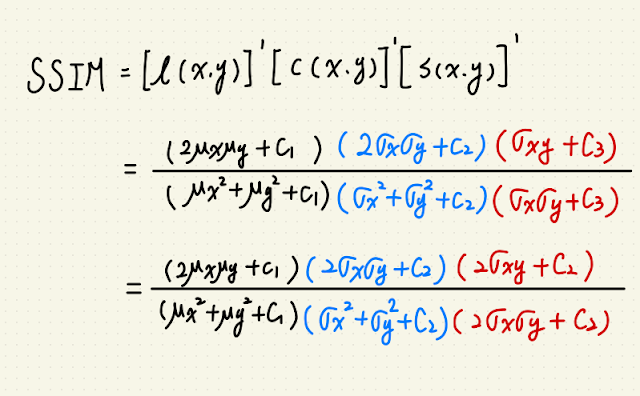
這篇是 SSIM 系列第三篇,接續前篇 使用 PyTorch 實做 2D 影像捲積,
要來談一下 SSIM 如何在不均勻光源下優化 SSIM。
如果你是剛開始接觸 SSIM 的人,可能會跟我一樣看過一篇幫愛因斯坦去噪的實現文章。
沒錯,當初我也是看到愛因斯坦的臉逐漸浮現,才覺得 SSIM 可以拿來解工程問題!
只是愛因斯坦那篇的調節亮度方法對於工程來說太過理想化,
問題在於他是把整張圖片的像素值乘以 0.9 調亮度!
這樣的話 SSIM 算法裡面的變異數項是不會變的,只有考慮到平均數項,
所以他做出來的 SSIM 值不會差太多。


但是現實世界是很絢爛多彩且難以預測的,
就像我前兩天載室友出門,停等紅燈時他突然發生奇怪的聲音,
轉頭問他在幹麻?
:我在跟你的機車排氣管對頻。

實務上,我們可能會面對不均勻光源的問題,就像是街邊的燈光:

這燈光很糟糕,比忘記簽聯絡簿的國小學童還糟糕,
因為它的光源只會影響照片的一部分,而且還會隨著距離遞減。
如果使用原版的 SSIM 方法對比這種有無開燈的照片,
則 SSIM值會不可避免的大幅下降,
但這兩張照片的前景內容物(e.g. 人、車、直升機、脫光衣服在路上奔跑的人)一樣對吧?
所以在基於前景的情況下,有些時候我們會希望有無開燈的照片應該要一樣,
數學上也就是得到理想值為 1 的 SSIM 值。
(實在是繞口令,讓我想到事件攝影機。)
要解這個問題就要先了解 SSIM 的本質,
SSIM 是由 sliding window 來解圖片中各自區域均值、變異數,還有兩張圖片的共變數所構成。
而二維的 window 又是由一維的 kernel (通常是 Gaussian)矩陣相乘得到,
基本上 OpenCV 裡面提供的方法是這樣:
nkernel = cv2.getGaussianKernel(11, 1.5)
nwindow = np.outer(nkernel, nkernel.transpose())
往 cv2.getGaussianKernel 裡面看,我們可以知道這條函式來自 getGaussianKernelBitExact:

再往 getGaussianKernelBitExact 裡面看:

重點是 158, 181 行運算的兩個迴圈,他們在幫忙算高斯核並歸一化。
我們的重點是歸一化,以前的簡易版 OpenCV Source Code 大概長這樣:
def getGaussianKernel(M, std):
n = np.arange(0, M) - (M - 1.0) / 2.0
sig2 = 2 * std * std
w = np.exp(-n ** 2 / sig2)
muli = 1/sum(w[:])
wn = w * muli
return wn
這種歸一化的一維高斯核長得像是:

扁扁有點可愛,像是軟趴趴的史萊姆。
但是這樣可能會造成一些問題,
讓我們看看非歸一化的原始高斯核:

def ourGaussianKernel(M, std):
n = np.arange(0, M) - (M - 1.0) / 2.0
sig2 = 2 * std * std
w = np.exp(-n ** 2 / sig2)
# muli = 1/sum(w[:])
# wn = w * muli
return w
def ssim_Normalized(img1, img2):
C1 = (0.01 * 255)**2
C2 = (0.03 * 255)**2
img1 = img1.astype(np.float64)
img2 = img2.astype(np.float64)
nkernel = cv2.getGaussianKernel(11, 1.5)
nwindow = np.outer(nkernel, nkernel.transpose())
nmu1 = cv2.filter2D(img1, -1, nwindow)[5:-5, 5:-5]
nmu2 = cv2.filter2D(img2, -1, nwindow)[5:-5, 5:-5]
nmu1_sq = nmu1**2
nmu2_sq = nmu2**2
nmu1_mu2 = nmu1 * nmu2
nsigma1_sq = cv2.filter2D(img1**2, -1, nwindow)[5:-5, 5:-5] - nmu1_sq
nsigma2_sq = cv2.filter2D(img2**2, -1, nwindow)[5:-5, 5:-5] - nmu2_sq
nsigma12 = cv2.filter2D(img1 * img2, -1, nwindow)[5:-5, 5:-5] - nmu1_mu2
nssim_map = ((2 * nmu1_mu2 + C1) *
(2 * nsigma12 + C2)) / ((nmu1_sq + nmu2_sq + C1) *
(nsigma1_sq + nsigma2_sq + C2))
return nssim_map.mean()
def ssim_Unnormalized(img1, img2):
C1 = (0.01 * 255)**2
C2 = (0.03 * 255)**2
img1 = img1.astype(np.float64)
img2 = img2.astype(np.float64)
kernel = ourGaussianKernel(11, 1.5)
window = np.outer(kernel, kernel.transpose())
mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5]
mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
mu1_sq = mu1**2
mu2_sq = mu2**2
mu1_mu2 = mu1 * mu2
sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
ssim_map = ((2 * mu1_mu2 + C1) *
(2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
(sigma1_sq + sigma2_sq + C2))
return ssim_map.mean()
if __name__=='__main__':
img1_path = 'img1.png'
img2_path = 'img2.png'
kernelSize = 21
light = list(map(np.uint8, gkern(kernlen=kernelSize, std=1.5)*100))
img1 = np.random.randint(0, 150, size=(100, 100)).astype(np.uint8)
img2 = np.zeros_like(img1)
img2[:] = img1[:]
row = np.random.randint(int(kernelSize/2), img1.shape[0] - int(kernelSize/2))
col = np.random.randint(int(kernelSize/2), img1.shape[1] - int(kernelSize/2))
times = np.random.randint(1, 100)
for i in range(0, times):
img2[row:row + kernelSize, col:col + kernelSize] += light
img2 = np.clip(img2, 0, 255)
print("This is Normalized): " + str("{:.5f}".format(ssim_Normalized(img1, img2))))
print("This is Unnormalized): " + str("{:.5f}".format(ssim_Unnormalized(img1, img2))))
親測可用:

2023 – 11
瑞鼎 – 觸控演算法工程師
1. 客戶需求專案支援
2. 觸控演算法開發與維護
3. 觸控演算法數據分析
Q1-1. 不使用 size of 算出這個結構佔用記憶體大小
struct ST
{
int I;
float F;
}AA;
解答:
struct ST
{
int I;
float F;
}AA;
int mysize(struct ST* a)
{
return (char*)(a + 1) - (char*)a;
}
int main()
{
AA.I = 10;
AA.F = 4.5;
printf("Size of AA: %dn", mysize(&AA));
return 0;
}
Terminal:
Size of AA: 8
可以這樣解的原因是結構變數指標+1 就是獲得這個結構變數後的記憶體位置,
用 char* 算是因為 char 佔用 1 Byte。
Q1-2. 用 C 實現 $ sum_{x=0}^{2} frac{2^{x}e^{x-1}}{32}$,不能使用 division,
並把整數與浮點數部份分別存入 AA 結構。
($e^{-1}=0.367879, e^{0}=1, e=2.718281$)
解答:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
struct ST
{
int I;
float F;
}AA;
int main()
{
int size = 3;
float *exp = malloc((size + 1) * sizeof(float));
exp[0] = 0.367897;
exp[1] = 1.0;
exp[2] = 2.718281;
exp[3] = 0.0;
for(int x=0; x<size; x++)
{
float bx = 2.0;
bx = pow(bx, (x-5));
exp[size+1] = exp[size+1] + bx*exp[x];
}
AA.I = (int)exp[size+1];
AA.F = exp[size+1] - AA.I;
printf("Result int part: %d, float part: %f", AA.I, AA.F);
return 0;
}
Terminal:
Result int part: 0, float part: 0.413782
除了那個 pow 的 MATH.h 不太確定能不能用外,
其他東西還蠻直覺的。
Q2.利用指標反轉陣列 array arr[7] ={1,2,3,4,5,6,7}
解答:
void swap(int *head, int *tail)
{
*head = (*head)^(*tail);
*tail = (*head)^(*tail);
*head = (*head)^(*tail);
}
int main()
{
int arr[7] = {1,2,3,4,5,6,7};
int *head = &arr[0];
int *tail = &arr[6];
while(head<tail)
{
swap(head, tail);
head++;
tail--;
}
for (int i = 0; i < 7; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
Terminal:
7 6 5 4 3 2 1
Q3. array arr={1,3,5,7,9,11,13,17} ,用二分搜尋法找出 11 的 index 為何?
解答:
int find(int* arr, int H, int T, int target)
{
if(H==T) {return H;}
if (target < arr[(int)((H + T)/2)])
{
return find(arr, H, (int)((H + T)/2), target);
}
else
{
return find(arr, (int)((H + T)/2)+1, T, target);
}
}
int main()
{
int arr[8] = {1,3,5,7,9,11,13,17};
int target = 11;
int res = find(arr, 0, 7, 11);
printf("Index of 11: %d", res);
return 0;
}
Terminal:
Index of 11: 6
Q4.下面這段函式定義是否合法?
Q5.為什麼它合法或不合法?
int* fun(int *x){return &x*&x;}
float* fun(float *x){return &x*&x;}
int main()
{
int x1 = 4;
float x2 = 4.5;
int* result1 = fun(x1);
float* result2 = fun(x2);
return 0;
}
解答:
Q4 不合法
Q5 主要有兩個原因:
第一個是沒給編譯器定義,這關係到函式多載(Function Overloading),
在 C 裡面就不允許函式多載、不同 IO 共用同一個函式名稱,
在 CPP 的話就允許,但是這邊沒說到用 gcc or g++ 編譯。
第二個是指標觀念,當函式傳入 *x,則函式內的 &x 等價 **x。
雙重指標 **x 沒有辦法直接做乘法運算。
心得
現場我有把 Q2, Q3 解出,
Q1-1肯定是我自己寫錯,Q1-2 第一眼看成積分直接空白,回來越想越不對。
Q4, Q5 可能是我 CPP 寫太多直覺以為只考函式多載,就騰了合法兩字送出,
還大膽解釋了一下。
沒想到裡面還有藏指標(汗。
以上都是英文出題,但是我沒記好英文全文,所以就憑自己印象寫出來,
如有筆誤歡迎來信指正。
這次是 104 主動投遞,人資主動打來約時間,
我也問了在職的話能不能一面線上?
結果是要到新竹現場考試,也通知筆試沒過就不面試。
行前還要我準備碩論跟部落格的報告。
這次整個面試流程大概是我提早半個小時到瑞鼎,
櫃台帶我去一樓小房間,
約定時間快到時,一位看起來像是人資(?)的人進來發考卷說寫半小時。
考完後人資將考卷拿給主管批改,過大概二十分鐘下來說我沒過資格,
還問我會不會出去?
OS:這不廢話嗎?不然你以為我怎麼出現在這裡?
嚴重懷疑你有特異功能看得到我的隱形直昇機或是隱形任意門。
雖然回家想想自己解得不甚理想,但是從頭到尾都沒見到主管這點讓我有點火大。
準備了一堆東西連主管都沒見著,幹麻不讓我線上開筆記本實況寫程式就好了?
以上。