背景:
這是用在一個環境監測的系統,
影像方面可以在光影下利用成色來判別不特定形狀的物件偵測模型。
會有這種不特定形狀的規格,
是配合甲方需求,否則機器學習訓練特定物件即可。
但此不特定物件偵測模型為我既有技術轉移,
未來應該會開一篇來解說,以下簡稱檢測模型。
瓶頸:
這次專案的瓶頸在於希望盡可能的提昇檢測速度,
並且讓一臺正常的 PC 服務約 200支監視鏡頭。
這是我第一次用一臺 PC服務 200支鏡頭,
之前專案大概是 8支攝影鏡頭,
所以要考慮計算資源的分配。
解決之路:
我一開始想讓這 200支鏡頭都連上 RTSP,
定時去啟動檢測任務。
遇到第一個問題是初始化資源用得太多。
因為一開始我用迴圈去一支一支初始化攝影機,
這麼大規模的 RTSP 連接量,
會讓原本已經連上的攝影機又斷線 -> 重複連線。
由於 200 路 RTSP 的全量維持長連線搶佔了大量 Socket 資源與網路頻寬,導致嚴重的封包遺失,觸發 OpenCV 的斷線重連機制,陷入惡性循環,最終造成系統崩潰與遠端連線中斷。
後來我先改一個讓遠端可以動的架構,
把這 200支分 10組,每 6分鐘就算一組 20支左右的鏡頭檢測任務,
並在每組裡面採用 ThreadPool 開 5個 worker 去執行任務,
也就是說我最多會有 5個檢測任務在跑,
跑完了就去拿組內剩下的攝影機任務。
這樣是稍微能跑了,但是對於單支攝影機檢測間隔來說太長了,
會來到一個小時檢測一次。
並且因為仍是維持全部 RTSP 在線架構,
會有斷線重連的問題。
最終架構:
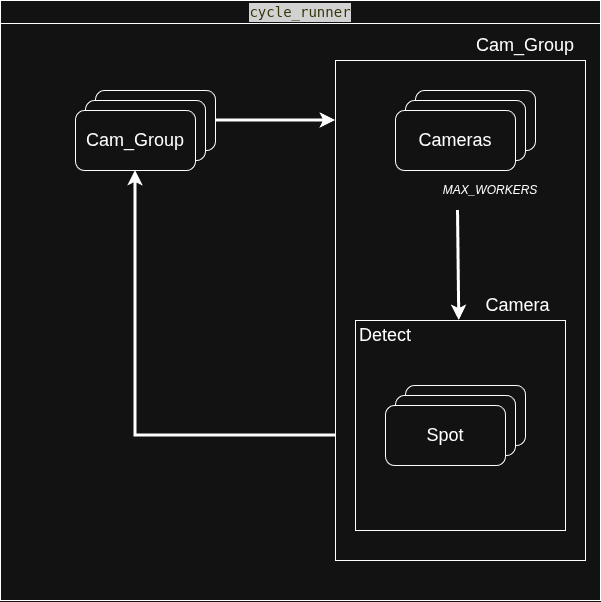
最後我設計了隨選連線的架構,
需要檢測時再讓鏡頭連上 RTSP,
雖然這樣每輪檢測都需要對鏡頭重新連線,
並在偵測完畢立即釋放資源。
這樣不僅能根絕斷線重連的問題,
且可以有效縮短單支攝影機的檢測間隔。
成果:
200支攝影機跑一輪檢測的時間大約會是 5分鐘,
也就是說單支攝影機的檢測間隔也會是 5分鐘,
比一個小時的間隔來說提升了 1200%。
並且在檢測模型內含有物件偵測模型且在 5 個 Worker 併發的情境下,
透過即時的資源回收,將系統 RAM 穩定壓制在 1.8GB 以內,
驗證了此資源調度架構的高效能。
另外整合了 Flask Web API,實現了檢測目標的動態遮蔽(Mute)與即時狀態查詢,增加了系統操作的靈活性。
發佈留言