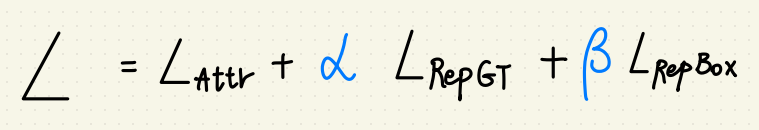
承上文:
ZLUDA 拓荒之路 – 榨乾 Intel CPU 算力的中短期方案
先說結論:
ZLUDA 目前在我的環境測試起來並不支援一些好棒棒框架,
像是 PyTorch、Numba 之類的,雖然我沒有測試,但是有足夠信心認為 Tenserflow 也不支援。
先附上我的環境:
OS: Ubuntu 22.04
Intel GPU: UHD 770
我的測試方式是下載 ZLUDA 的 Releases 2 的版本
這個解開會有一個資料夾內含兩個 .so 檔,
將想執行的檔案放在與 .so 檔同個資料夾下執行即可。
但是像作者一樣測試 GeekBench 5.2.3 的話是會過的,
數據差別不大,至於為什麼測出沒有 Sobel 測項?
因為要有那個測項要付錢啊啊啊啊啊!
(GeekBench 5.2.3 官網下載點)
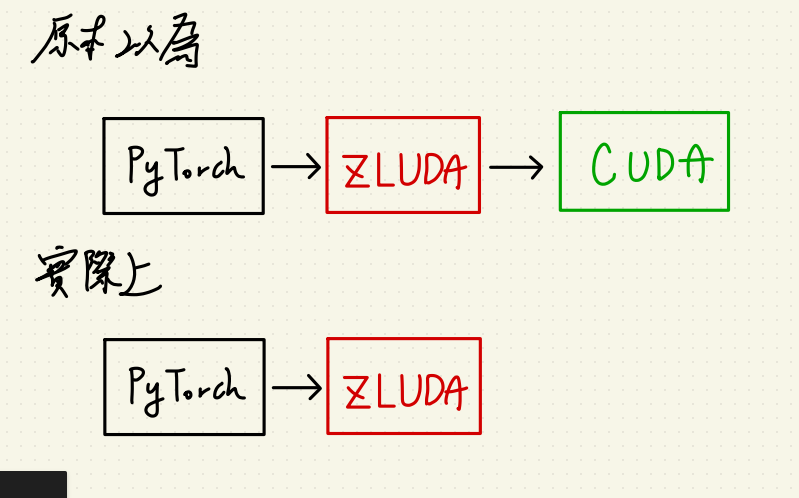
接著我要勘誤上篇關於 CUDA 與 ZLUDA 的引用關係,
後來發現 ZLUDA 使用上應該是要完全取代 CUDA 的,
所以你不裝 CUDA 它也會跑得起來。
但由於 ZLUDA 並沒有支援 CUDA 的所有功能,
加上我猜測它是針對某版的 CUDA 來開發的,
所以 API 串接那邊也會報錯,而 CUDA 本家會動態連結這些函式,
導致 ZLUDA 的支援性很低。

最後來談談這東西的未來性還有有志之士可以怎麼發展下去?
我認為這東西會踩到 Intel 把拔的 oneAPI 計畫,
短時間內應該就這樣了。
所以除非有誰與 Nvidia, Intel 同時具有競爭關係又做 CPU + GPU?
ZLUDA 才會復活。
(望向蘇媽)
有志之士的話可以接著試試看,
因為我曾經在 Python 3.7 及上述環境中讓 Numba 呼叫到 Intel UHD 770 的硬體。
以下是給有志之士的簡易指南:
1.確認自己手上有(消費級 Intel CPU 超過 8代 或 Intel XE CPU)且 (有內顯)
2.裝 Intel 內顯驅動(Ubuntu 20.04 可以參考這篇, 22.04 也可以參考但記得不用降內核)
3.確認內顯驅動有裝好xD
4.裝 Python3.7 + Numba 0.49 – 0.58 版本,我印象當時是裝這區間。
5.下載 ZLUDA 的 Releases 2 的版本 來測試
裝驅動的時候要特別注意,
我在那邊卡很久,不一定第一次會裝好,
重複裝的時候不要反安裝到這個 gawk libc6-dev udev,
這套件就算你不 –purge 都會幫你把 Gnome 還有一拖拉庫東西 拆掉 :)
最後講一下 Intel 的 oneAPI,
我用過裡面的 Intel® oneAPI Base Toolkit + Intel® AI Analytics Toolkit(PyTorch 最佳化)
用同一台機器來計算同一份呼叫到 PyTorch 的檔案,
用 Intel 方案的環境會算得比純 PyTorch 版本還要慢。
就是大家可以收一收回家了,感謝各位。
如果有志之士想討論 or Intel 官方想維護一下自己的東西(#。
歡迎聯絡我:
wuyiulin@gmail.com