上個月被派了幾個工項,
其中一個是解我們開單員拍到的車牌照片。
相信各位做影像的同行在驗證自己演算法的時候,
總是像我一樣眼見為憑、需要把圖片秀出來對吧?
在很多的 OpenCV 教學文裡面都教我們用這行程式碼關掉視窗:
cv2.imshow('Image', img)
cv2.waitKey(0)但是用這行程式碼的問題是如果你按了視窗右上角的 “X” 來關掉視窗,
那麼你的程式就會卡住,因為 OpenCV 不知道視窗被關掉了,
所以視窗的程序就繼續執行跟你演。
我每次遇到這狀況就快要中風,
為了避免各位同行也中風我在此提供解決方法。
cv2.imshow('Image', img)
while True:
if (cv2.getWindowProperty('Image', cv2.WND_PROP_VISIBLE) <= 0 or cv2.waitKey(1) > 0):
cv2.destroyWindow('Image')
break
原理是去檢查名稱叫做 Image 的視窗狀態,
如果他被關掉了,那就把視窗的程序結束掉讓程式就繼續進行。
至於為什麼要放 waitKey(1) 而不是 waitKey(0),
那是因為 waitKey(0) 放在條件式裡面會像王寶釧苦守寒窯十八年,
等你在視窗按下任意鍵。
如果你又按 “X” 把視窗結束掉了,那就真的老死不相往來了。
那你說 CPP 裡面怎麼辦呢?有 CPP 的版本嗎?
我也覺得很奇怪,Python 版的 OpenCV 理論上是 bind CPP版 的 OpenCV ,
兩邊實現應該會一樣?
但是 CPP 中 waitKey(0) 可以偵測視窗關掉(也就是按右上角”X”也能關掉視窗程序)。
以上,謝謝指教。

本篇文章來自 想知道網戀對象有沒有修圖嗎?試試看這款修圖偵測機器人! 的續篇,
不是,我是說有些人可能不適合做立委、適合做總統!
所以我用 CPP 實現了需要數學運算的 DCT 方法,
這邊比較需要注意的是因為我選用的讀圖方式是 OpenCV 的 CPP 函式庫,

相關開源我更新在:
https://github.com/wuyiulin/GraphAppBot
想要測試一下這個服務:
如果有任何問題歡迎聯絡我:
wuyiulin@gmail.com
前陣子在咱們一群影像愛好者的群組開始流傳一套程式,
一套號稱能檢測愛情動作片封面詐欺的程式!
什麼?天底下有這等好事?
於是我找到了開發這套程式的仁兄要到了原始論文,
認為他實現得不夠完美,間接促使我完成這項服務。
這篇文章可以幫你得出一個修圖參考值
(但某些情況不適用,文後會補充說明。)
接著會介紹論文以及背後數學原理,
對於檢測服務比較有興趣可以直接跳到後面。
原理
本文是 Analyzing Benford’s Law’s Powerful Applications in Image Forensics 這篇論文的延伸應用:
要講解這篇論文就要先解釋什麼是 Benford’s Law?
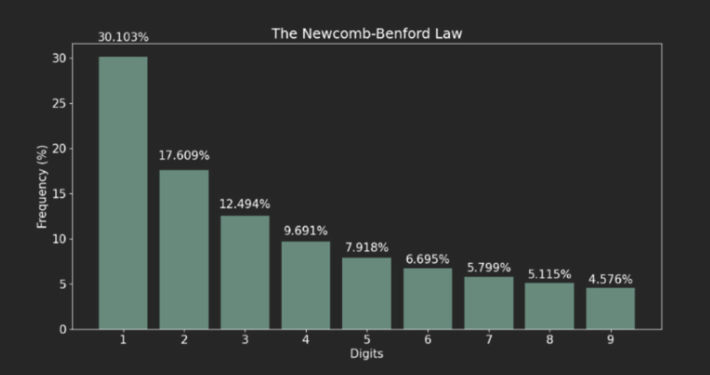
Benford’s Law 的概念就是人類世界中隨機數其實並不隨機,
其中數據的首位數字是遵循某種規律,這個規律就是 Benford’s Law。
Benford’s Law 公式:
$F_a = log_{10}{(frac{a+1}{a})}$, for all a = 1,2,…,9
這樣算起來會呈現由首位數字出現比率是 1 往 9 遞減的一個分佈:
舉個 Benford’s Law 的例子,
如果他們沒有說謊的話,這一萬人的存款首位數字應該會符合 Benford’s Law。
而論文本意是拿這個結論做二次壓縮來估測 JPEG 的壓縮率,
有興趣的大家可以自己閱讀一下論文。
實作

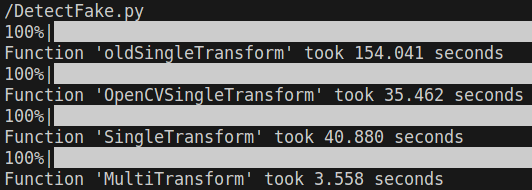
身為一個影像從業者,
一定要做到比內建函式庫快!
俗話說得好:
要看一個人會不會做立委,就要看他怎麼做立委。
我是說要加速就要從數學看起,所以讓我們來看一下公式:
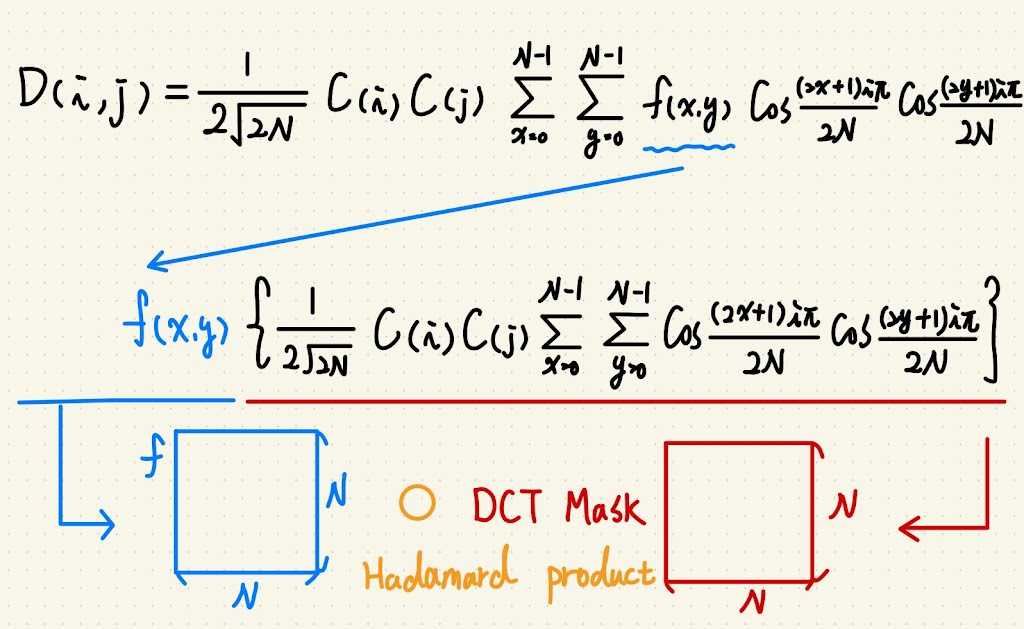
其中 $D(i, j)$ 是轉換後的值,$i, j$ 是位置參數;
$f(x, y)$ 是原始圖片的亮度值,$x, y$ 也是位置參數。
發現亮度值可以提出來,其中位置參數可以自己組一個矩陣相乘,
我們暫且把包含所有 $i, j$ 組合的稱為母矩陣。
這個母矩陣可以重複用,就不用每個區塊都要算。
(原始圖片會被 N*N 的小區塊分割,N 通常是 8。)
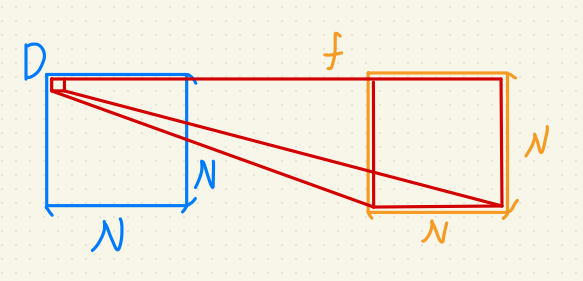
因為一組 $i, j$ 負責一組子矩陣,
所以如果輸出入尺寸相同,母矩陣大小為: $N * N * N * N$
於是我用這方法寫了一個 Mask 法,
的確速度與 OpenCV 內置函數比肩了,但是還沒有超越(#。
再加速
於是我又對平行運算生起了一絲邪念,
如果我宣告一組共享記憶體紀錄首位數字,
並對計算每個區塊的計算採取平行運算呢?
起初我是用 Lock 方法,後來發現這樣設計寫入的時候會有 Race Condition 問題,
後來便採取 Lock free 實作,缺點是佔用的記憶體較多。
數據判讀
目前線上提供服務的機器人都是使用 DownSample 方法做計算。
特別需要說明的是手機原生相機就會做白平衡、明暗部校正,
尤其是 iPhone 做得非常優秀。
開源
原始論文使用 Uncompressed Colour Image Database 資料庫,
探討使用原始無損圖片如何估計 JPEG 壓縮率,
所以本文的物理意義是估算原始無損圖片與輸入圖片的差異度。
本文估計值僅供參考,
窮盡科技之力後不如鼓起勇氣約網戀對象出來走走!

最近上班遇到一些圖片顏色偏離原色,
身為影像工程從業者就會想自己寫 3A算法來校正。
而自動白平衡便是 3A 中的其中 1A – 南湖大山!
而自動白平衡便是 3A 中的其中 1A – Auto White Balance
自動白平衡的核心就是解決圖片色偏的方法,
大都是找到圖片中的參考值,
再用參考值及不同方法去對整張圖片做校正。
像是灰色世界算法就是拿全圖片的加總的三通道均值當作參考值,
再拿這個參考值除以三通道分別均值做成三通道的增益,
得到三通道增益後分別對通道相乘。
今天提到的完美反射核心,它的概念是相信圖片中有一群接近白色的區塊,
因為 RGB or BRG 的世界裡面 (255, 255, 255) 就是白色嘛,
所以有點像找到這塊邊長為 255 的正方形中那群最遠離原點 (0, 0, 0) 的那群點。
找到那群點後,再求得這群的均值作為參考值,
參考值除以各通道的均值就能得到各通道的增益,
最後再拉回去與原圖相乘 -> 結案。
def AutoWhiteBalance_PRA(imgPath, ratio=0.2): # 自動白平衡演算法_完美反射核心, 0 < ratio <1.
BGRimg = cv2.imread(imgPath)
BGRimg = BGRimg.astype(np.float32) # 將資料格式轉為 float32,避免 OpenCV 讀圖進來為 np.uint8 而造成後續截斷問題。
pixelSum = BGRimg[:,:,0] + BGRimg[:,:,1] + BGRimg[:,:,2]
pexelMax = np.max(BGRimg[:,:,:]) # 求三通道加總最大值作為像素值拉伸指標
row , col, chan = BGRimg.shape[0], BGRimg.shape[1], BGRimg.shape[2]
pixelSum = pixelSum.flatten()
imgFlatten = BGRimg.reshape(row*col, chan)
thresholdNum = int(ratio * row * col)
thresholdList = np.argpartition(pixelSum, kth=-thresholdNum, axis=None) # 由右至左設定閾值位置,並得到粗略排序後的索引表。
thresholdList = thresholdList[-thresholdNum:] # 取得索引表中比閾值大的索引號
blueMean, greenMean, redMean, i = 0, 0, 0, 0
for i in thresholdList:
blueMean += imgFlatten[i][0]
greenMean += imgFlatten[i][1]
redMean += imgFlatten[i][2]
blueMean /= thresholdNum
greenMean /= thresholdNum
redMean /= thresholdNum
blueGain = pexelMax / blueMean
greenGain = pexelMax / greenMean
redGain = pexelMax / redMean
BGRimg[:,:,0] = BGRimg[:,:,0] * blueGain
BGRimg[:,:,1] = BGRimg[:,:,1] * greenGain
BGRimg[:,:,2] = BGRimg[:,:,2] * redGain
BGRimg = np.clip(BGRimg, 0, 255)
BGRimg = BGRimg.astype(np.uint8)
return BGRimg


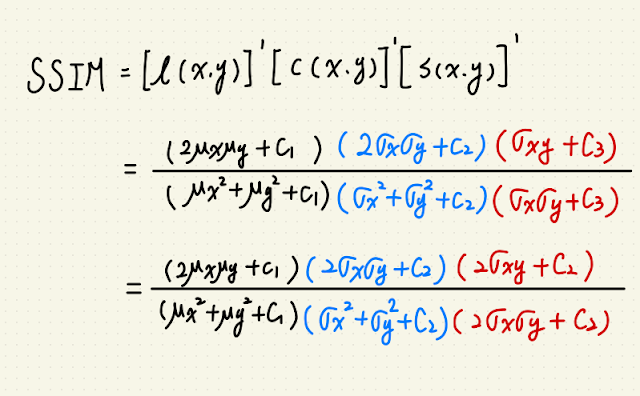
這篇是 SSIM 系列第三篇,接續前篇 使用 PyTorch 實做 2D 影像捲積,
要來談一下 SSIM 如何在不均勻光源下優化 SSIM。
如果你是剛開始接觸 SSIM 的人,可能會跟我一樣看過一篇幫愛因斯坦去噪的實現文章。
沒錯,當初我也是看到愛因斯坦的臉逐漸浮現,才覺得 SSIM 可以拿來解工程問題!
只是愛因斯坦那篇的調節亮度方法對於工程來說太過理想化,
問題在於他是把整張圖片的像素值乘以 0.9 調亮度!
這樣的話 SSIM 算法裡面的變異數項是不會變的,只有考慮到平均數項,
所以他做出來的 SSIM 值不會差太多。


但是現實世界是很絢爛多彩且難以預測的,
就像我前兩天載室友出門,停等紅燈時他突然發生奇怪的聲音,
轉頭問他在幹麻?
:我在跟你的機車排氣管對頻。

實務上,我們可能會面對不均勻光源的問題,就像是街邊的燈光:

這燈光很糟糕,比忘記簽聯絡簿的國小學童還糟糕,
因為它的光源只會影響照片的一部分,而且還會隨著距離遞減。
如果使用原版的 SSIM 方法對比這種有無開燈的照片,
則 SSIM值會不可避免的大幅下降,
但這兩張照片的前景內容物(e.g. 人、車、直升機、脫光衣服在路上奔跑的人)一樣對吧?
所以在基於前景的情況下,有些時候我們會希望有無開燈的照片應該要一樣,
數學上也就是得到理想值為 1 的 SSIM 值。
(實在是繞口令,讓我想到事件攝影機。)
要解這個問題就要先了解 SSIM 的本質,
SSIM 是由 sliding window 來解圖片中各自區域均值、變異數,還有兩張圖片的共變數所構成。
而二維的 window 又是由一維的 kernel (通常是 Gaussian)矩陣相乘得到,
基本上 OpenCV 裡面提供的方法是這樣:
nkernel = cv2.getGaussianKernel(11, 1.5)
nwindow = np.outer(nkernel, nkernel.transpose())
往 cv2.getGaussianKernel 裡面看,我們可以知道這條函式來自 getGaussianKernelBitExact:

再往 getGaussianKernelBitExact 裡面看:

重點是 158, 181 行運算的兩個迴圈,他們在幫忙算高斯核並歸一化。
我們的重點是歸一化,以前的簡易版 OpenCV Source Code 大概長這樣:
def getGaussianKernel(M, std):
n = np.arange(0, M) - (M - 1.0) / 2.0
sig2 = 2 * std * std
w = np.exp(-n ** 2 / sig2)
muli = 1/sum(w[:])
wn = w * muli
return wn
這種歸一化的一維高斯核長得像是:

扁扁有點可愛,像是軟趴趴的史萊姆。
但是這樣可能會造成一些問題,
讓我們看看非歸一化的原始高斯核:

def ourGaussianKernel(M, std):
n = np.arange(0, M) - (M - 1.0) / 2.0
sig2 = 2 * std * std
w = np.exp(-n ** 2 / sig2)
# muli = 1/sum(w[:])
# wn = w * muli
return w
def ssim_Normalized(img1, img2):
C1 = (0.01 * 255)**2
C2 = (0.03 * 255)**2
img1 = img1.astype(np.float64)
img2 = img2.astype(np.float64)
nkernel = cv2.getGaussianKernel(11, 1.5)
nwindow = np.outer(nkernel, nkernel.transpose())
nmu1 = cv2.filter2D(img1, -1, nwindow)[5:-5, 5:-5]
nmu2 = cv2.filter2D(img2, -1, nwindow)[5:-5, 5:-5]
nmu1_sq = nmu1**2
nmu2_sq = nmu2**2
nmu1_mu2 = nmu1 * nmu2
nsigma1_sq = cv2.filter2D(img1**2, -1, nwindow)[5:-5, 5:-5] - nmu1_sq
nsigma2_sq = cv2.filter2D(img2**2, -1, nwindow)[5:-5, 5:-5] - nmu2_sq
nsigma12 = cv2.filter2D(img1 * img2, -1, nwindow)[5:-5, 5:-5] - nmu1_mu2
nssim_map = ((2 * nmu1_mu2 + C1) *
(2 * nsigma12 + C2)) / ((nmu1_sq + nmu2_sq + C1) *
(nsigma1_sq + nsigma2_sq + C2))
return nssim_map.mean()
def ssim_Unnormalized(img1, img2):
C1 = (0.01 * 255)**2
C2 = (0.03 * 255)**2
img1 = img1.astype(np.float64)
img2 = img2.astype(np.float64)
kernel = ourGaussianKernel(11, 1.5)
window = np.outer(kernel, kernel.transpose())
mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5]
mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
mu1_sq = mu1**2
mu2_sq = mu2**2
mu1_mu2 = mu1 * mu2
sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
ssim_map = ((2 * mu1_mu2 + C1) *
(2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
(sigma1_sq + sigma2_sq + C2))
return ssim_map.mean()
if __name__=='__main__':
img1_path = 'img1.png'
img2_path = 'img2.png'
kernelSize = 21
light = list(map(np.uint8, gkern(kernlen=kernelSize, std=1.5)*100))
img1 = np.random.randint(0, 150, size=(100, 100)).astype(np.uint8)
img2 = np.zeros_like(img1)
img2[:] = img1[:]
row = np.random.randint(int(kernelSize/2), img1.shape[0] - int(kernelSize/2))
col = np.random.randint(int(kernelSize/2), img1.shape[1] - int(kernelSize/2))
times = np.random.randint(1, 100)
for i in range(0, times):
img2[row:row + kernelSize, col:col + kernelSize] += light
img2 = np.clip(img2, 0, 255)
print("This is Normalized): " + str("{:.5f}".format(ssim_Normalized(img1, img2))))
print("This is Unnormalized): " + str("{:.5f}".format(ssim_Unnormalized(img1, img2))))
親測可用:

承上文:
ZLUDA 拓荒之路 – 榨乾 Intel CPU 算力的中短期方案
先說結論:
ZLUDA 目前在我的環境測試起來並不支援一些好棒棒框架,
像是 PyTorch、Numba 之類的,雖然我沒有測試,但是有足夠信心認為 Tenserflow 也不支援。
先附上我的環境:
OS: Ubuntu 22.04
Intel GPU: UHD 770
我的測試方式是下載 ZLUDA 的 Releases 2 的版本
這個解開會有一個資料夾內含兩個 .so 檔,
將想執行的檔案放在與 .so 檔同個資料夾下執行即可。
但是像作者一樣測試 GeekBench 5.2.3 的話是會過的,
數據差別不大,至於為什麼測出沒有 Sobel 測項?
因為要有那個測項要付錢啊啊啊啊啊!
(GeekBench 5.2.3 官網下載點)
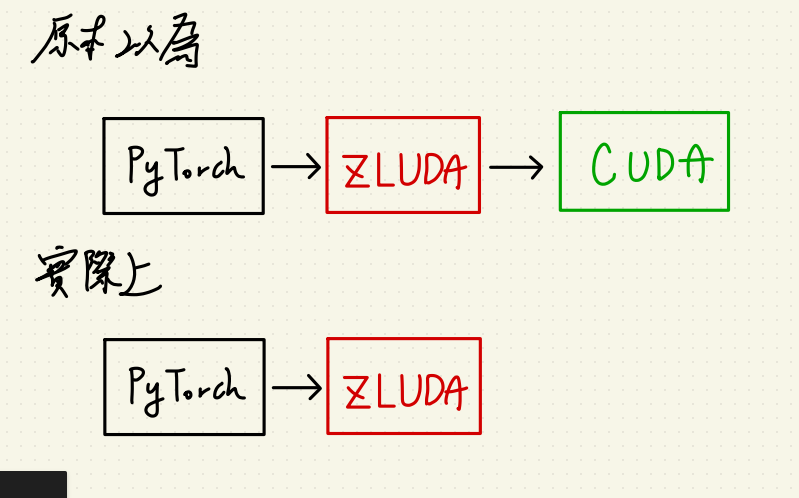
接著我要勘誤上篇關於 CUDA 與 ZLUDA 的引用關係,
後來發現 ZLUDA 使用上應該是要完全取代 CUDA 的,
所以你不裝 CUDA 它也會跑得起來。
但由於 ZLUDA 並沒有支援 CUDA 的所有功能,
加上我猜測它是針對某版的 CUDA 來開發的,
所以 API 串接那邊也會報錯,而 CUDA 本家會動態連結這些函式,
導致 ZLUDA 的支援性很低。

最後來談談這東西的未來性還有有志之士可以怎麼發展下去?
我認為這東西會踩到 Intel 把拔的 oneAPI 計畫,
短時間內應該就這樣了。
所以除非有誰與 Nvidia, Intel 同時具有競爭關係又做 CPU + GPU?
ZLUDA 才會復活。
(望向蘇媽)
有志之士的話可以接著試試看,
因為我曾經在 Python 3.7 及上述環境中讓 Numba 呼叫到 Intel UHD 770 的硬體。
以下是給有志之士的簡易指南:
1.確認自己手上有(消費級 Intel CPU 超過 8代 或 Intel XE CPU)且 (有內顯)
2.裝 Intel 內顯驅動(Ubuntu 20.04 可以參考這篇, 22.04 也可以參考但記得不用降內核)
3.確認內顯驅動有裝好xD
4.裝 Python3.7 + Numba 0.49 – 0.58 版本,我印象當時是裝這區間。
5.下載 ZLUDA 的 Releases 2 的版本 來測試
裝驅動的時候要特別注意,
我在那邊卡很久,不一定第一次會裝好,
重複裝的時候不要反安裝到這個 gawk libc6-dev udev,
這套件就算你不 –purge 都會幫你把 Gnome 還有一拖拉庫東西 拆掉 :)
最後講一下 Intel 的 oneAPI,
我用過裡面的 Intel® oneAPI Base Toolkit + Intel® AI Analytics Toolkit(PyTorch 最佳化)
用同一台機器來計算同一份呼叫到 PyTorch 的檔案,
用 Intel 方案的環境會算得比純 PyTorch 版本還要慢。
就是大家可以收一收回家了,感謝各位。
如果有志之士想討論 or Intel 官方想維護一下自己的東西(#。
歡迎聯絡我:
wuyiulin@gmail.com
在開始壞壞之前,我們先了解一下 ZLUDA 是什麼?
ZLUDA 是一款很有理想的開源套件,
號稱能模擬閉源的 CUDA ,只用 Intel CPU 就能執行現有的 CUDA code。
但實際用下去發現還是有一點小限制,
畢竟作者本人在 2021 年跳坑了(用膝蓋猜是被 I社把拔的 Arc 顯卡利益衝突到)。
目前 Linux 系列只支援到 5.19 Kernel,
如果你跟我一樣用 Ubuntu 22.04 也是失去支援。
Windows 戰場就優質許多,
只要你是臺正常的家用主機應該都能用!
畢竟這年代誰還用奔騰與賽揚或是 Atom 當家用 CPU 你說對吧?
但還是跟一票嵌入式 CPU 說掰掰了,
因為 ZLADA 主要壓榨的是 UHD 顯示晶片的算力。
話不多說,先來下載在 windows 上面用:
下載完解壓縮,你的框架套件(PyTorch 等)也不用重裝,
就直接:
zluda_wuth.exe -- python your_py_file.py
就能跑了,484很方便?
Ummmm,通常是不會那麼方便啦。
有幾點要特別注意,因為這貨是模擬 CUDA 所以不是真的尻 CUDA 出來用。
你的框架套件配合 CUDA 版本要看 nvidia-smi 上面你裝的 Nvidia Driver 支援的比較準,
而不是 nvcc -V 出來的真實 CUDA 版本。
不然注入 zlida_with.exe 的時候會說你的 Driver 與 CUDA mismatch。
聽起來有點模糊對不對?
簡單來說,
如果你下 nvidia-smi 發現自己 Nvidia Driver 是 53X.xx 版,配合的 CUDA 是 12.2,
而 nvcc -V 出來的真實 CUDA 版本是 10.0?
那麼你 PyTorch 就要按照 Nvidia Driver 配合的 CUDA 裝,而不是裝 cu100 系列的 PyTorch。
這點要特別注意!
還有就是如果在 conda 環境內遇到 Python3.8 的 dll loss 問題,
需要重新安裝 Python ?
切記在 conda 裡面重新安裝 Python ,套件會繼承下來,
這會與之前舊有的 PyTorch 連動產生一些問題。
像是好事的 PyTorch 1.8.1 會喜歡幫你更新 typing_extensions,
如果你重新安裝了低版本的 Python (e.g. 3.8 -> 3.7)
會遇到 typing_extensions 錯誤,而且長得很像你程式寫錯:
File “C:UsersuserNameanaconda3envsmyenvlibsite-packagestyping_extensions.py”, line 874
def TypedDict(typename, fields=_marker, /, *, total=True, **kwargs):
^
SyntaxError: invalid syntax
莫急莫慌莫害怕,先查一下 typing-extensions 版本是不是被繼承?
是的話直接:
pip show typing-extensions pip uninstall typing_extensions pip install typing_extensions
我印象還因為 zluda 處理了一些 deadlock 問題,
還好天公疼憨人讓我順手解開了。
以上就能讓 ZLUDA 在 Windows 上順利跑起來!
結論時間:
ZLUDA 真的能取代低階 GPU (_050, _060)的 inference task 嗎?
以下情況是拿 Alder Lake 的 i5 去測的結論,
某些情況會比純 CPU inference 快一點,
但要 Costdown 還是想多了。
有進步,但不多!
承上篇:Structural Similarity(SSIM) 的 PyTorch 實現
由於我 3D 影像處理做太多(X) 2D 影像處理還沒有恢復記憶(O)
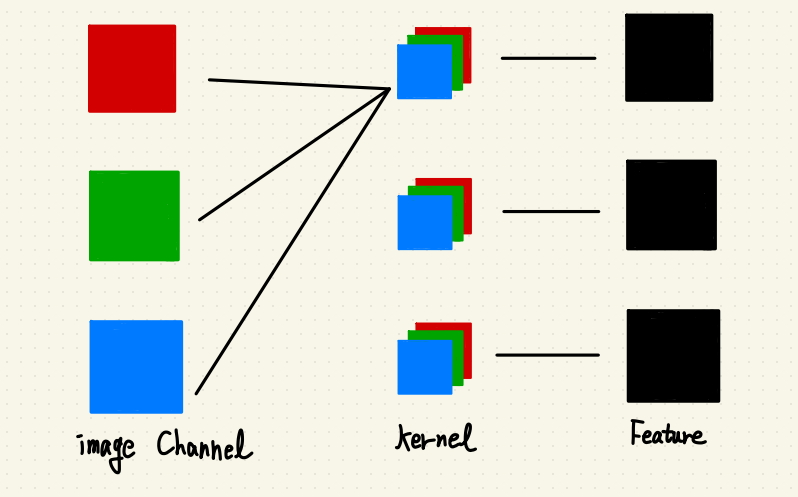
上次在刻高斯濾波的時候忘記 PyTorch Kit 的 Convolution 一個很重要的特性:
PyTorch 會參考其他通道的資訊啊!
其實這點也是無可厚非,畢竟 PyTorch 的初衷是給深度學習用的框架,
韓信點兵多多益善嘛!
所以 PyTorch 的 Convolution 流程大概是這樣:

顯而易見地,沒經過額外處理的話 SSIM值會超出邊界(0,1),
這違反了 SSIM 這項指標的意義。
所以我們要來看一下隔壁棚 2D影像處理套件 – OpenCV 怎麼做 2D 影像的 Convolution?
在 OpenCV 裡面,每個通道都是用同一顆 Kernel,但是會分離通道做 Convolution,
如下圖:

得到這個資訊後,我打算用分 Groups 來解這題。
PyTorch 中的 2D Convolution 有兩種,
一種是 torch.nn.Conv2d
另一是 torch.nn.functional.conv2d
前者只要設定好 Kernel 大小就能動,後者則可以提供使用自己 Kernel 的 API。
筆者這次使用後者,就以後者的 Document 來解釋:


首先我們要知道自己要分幾組 Group?
我們希望每個通道都各自做 Convolution ,而 RGB 圖片有三個通道,
所以我們的 Groups 應該設定三組。

再來需要注意上圖中 torch.nn.functional.conv2d 中的 weight,
這裡的 weight 代表的是 Kernel。
既然改了 Groups ,Kernel 的相應尺寸也要記得改變。
原本是 Kernel.shape = {3, 3, H, W} 要變成 {3, 3/3 = 1, H, W}。
這樣就能開心地模擬 OpenCV 的 2D Convolution 啦!
筆者在手刻 Kernel 的時候也遇到一些光怪陸離的問題,
預計下一篇會來寫這部份。

去年暑假我在公司寫了一支轉換程式,
關於把 YOLOv3, v3Tiny, v4 的 .weight 檔案轉換成 OAK 系列相機能用的 .blob 檔。
主要是公司那邊想用這東西來做物件追蹤,如果成了,就能大幅度的提升效率還有推理速度。
推理速度能提升是因為 OAK 相機是一顆 Edge 裝置,
裡面有類似 GPU 的 VPU,可以理解為裡面插了之前 Intel 推出的神經推理棒晶片,
不用把資料再塞回伺服器推理。
然後就不出意外的出意外了。
主要大概遇到三個階段性問題:
一、無法推理,模型轉換報錯。
二、可以推理,模型推理錯誤。
三、可以推理,Anchor 尺寸錯誤。
一、無法推理,模型轉換報錯:
先講 OAK 這相機的由來,OAK 相機其實是 Openvino 推的硬體,Openvino 背後又是我們偉大的牙膏廠(Intel)。
牙膏廠的文件大家也是知道的。
OAK 相機這東西太新,總之原廠還沒有支援完整的轉換套件,所以依照之前牙膏出的神經推理棒轉換流程去轉會出錯,無法在 OAK 上面執行。
(後來推估原因,應該是轉換凍結模型模型的時候有一些網路層沒轉到。)
我研究後發現,雖然 .weight 檔沒辦法一步轉換成 .blob,但是可以先轉成中繼格式 .pb 再轉成 .blob。
確定這個路線後,程式就分成兩部分:
一、1 將 YOLO 的 .wight 模型還有 .cfg (依賴 COCO資料集)轉成 .pb。
一、2 將 .pb 轉成 .blob。
二、可以推理,模型推理錯誤:
查了一些文件,轉過去後的確是能放在 OAK 相機上面跑,不會報錯,
但是檢測結果很異常。
會有物件框,但是 label 是錯的、Anchor 也不會隨著不同物件變動尺寸。
為了釐清到底是 .pb 出問題,還是 .blob 出問題?
我找了正職的同仁要了一份內部訓練的 .pb 檔案,
也在網路上找了一份確定正常的 .pb 預訓練模型,
將這兩者放入 Openvino 在個人電腦上模擬推理、確認轉換後的模型沒問題。
結果這步驟(一、1)就出錯,推測是轉換時沒有融合到 .cfg 的資訊,
導致 label 與 Anchor 出錯。
後來透過查詢 Github 還有詢問同仁的經驗,才把這部分搞定。
這部分是使用一個將 YOLOv3, v3Tiny, v4 轉成 .pb 的開源專案處理的。
三、可以推理,Anchor 尺寸錯誤:
解決完上述問題,放進 OAK 相機仍然出錯,這次的問題如同下圖:
最終獲得正確的輸出結果:

後續也將此流程整理為自動化 bat 程式,並在月會上報告、寫成教學手冊交由部門使用。
此專案提供了可信的評估依據,並初步探索了 OAK 相機的性能與使用方法。
目前程式已在 Github 上開源。
如果有任何問題,請聯絡我:
wuyiulin@gmail.com