假設各位都知道並了解 Cross Entropy 是什麼的前提下,
這篇文章主要提到 Focal Loss ,一種基於 Cross Entropy 的改進方法。
主要改進兩個方向:
- Data imbalanced
- Difficulty sample in weight ( Focal Loss )
首先我們先來比較 Cross Entropy 與 Focal Loss 的 function:
 |
| CE vs FL |
如上圖所見,
Alpha 負責解決 Data imbalanced、 Gamma 負責解決 Difficulty sample 的問題。
- Alpha
講解 Alpha 之前,先讓我們了解什麼是 Data imbalanced。
Data imbalanced 就是關於你的資料集,如果每個類別的樣本分布不均,
這樣模型就容易被樣本多的類別所決定。
模型被牽著鼻子走 -> 樣本少的類型容易分不好 -> 分類精準度就會遇到瓶頸。
 |
| 像是 Modelnet40 就有這種問題。 |
所以 Alpha 是一個 Vector ,把 Alpha 乘回原本該進去 CE 的分佈機率表,
便可以用來來平衡樣本少與樣本多的類別。
(個人是使用 總樣本數 / 該類別樣本數,作為該類別的 Alpha t 值)
- Gamma
Gamma 就比較難解釋了,
首先假設分類網路分對且高信心(i.e. 好分類樣本)的情況下
( assume y = 1 , p = 0.8 , gamma = 1):
原始的 CE 給出的 Loss 會是: -log(p) ~ 0.096
改進後的 FL 給出的 Loss 會是: (-1) * (1-p)^gamma * log(p) ~ 0.019
而在分類網路分對且低信心度(i.e. 難分類樣本)的情況下
( assume y = 1 , p = 0.2 , gamma = 1 ):
原始的 CE 給出的 Loss 會是: -log(p) ~ 0.698
改進後的 FL 給出的 Loss 會是: (-1) * (1-p)^gamma * log(p) ~ 0.559
在高信心度分類正確情況下,FL 的 Loss 會更低,
在低信心度分類正確情況下,FL 的 Loss 會更低,
這代表 FL 比 CE 更好對嗎?
如果妳到目前為止覺得我說的超對!
身高又超過 160、長髮過肩,麻煩聯絡我: wuyiulin@gmail.com
無論在哪個城市,我總是知道哪間牛排館最好吃。
只差一位無條件支持我的另一半!
在分類網路分錯且低信心度(i.e. 難分類樣本)的情況下
( assume y = 1 , p = 0.2 , gamma = 1 ):
原始的 CE 給出的 Loss 會是: -log(p) ~ 0.698
改進後的 FL 給出的 Loss 會是: (-1) * (1-p)^gamma * log(p) ~ 0.559
哇靠,怎麼 FL 給出的 Loss 比較低?
難分類的就算了,如果好分類的分錯怎麼辦?
在分類網路分錯且高信心度(i.e. 好分類樣本)的情況下
( assume y = 1 , p = 0.8 , gamma = 1 ):
原始的 CE 給出的 Loss 會是: -log(p) ~ 0.096
改進後的 FL 給出的 Loss 會是: (-1) * (1-p)^gamma * log(p) ~ 0.019
將近四倍的 Loss 值,超級優秀。
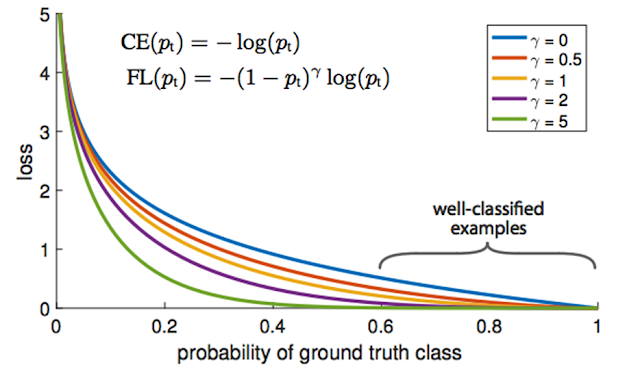 |
| 原論文中 gamma 值是 Hyperparameter 參照下所畫的曲線。 |
結論:
個人覺得 FL 的 Gamma 部分比較適合在精確度已經 push 到很極端的模型。
但是 Alpha vector 看起來倒是通用沒問題。
如果本篇數學部分推導有任何錯誤,
歡迎聯絡:wuyiulin@gmail.com
References